Módulo 5 do Curso de Engenharia de Prompt: Nível Expert
Prompting Multimodal
Rogério Marques
Seu instrutor nesta jornada
1. Fundamentos de Modelos de Visão e Linguagem (VLMs)
Até agora, nossos modelos eram como gênios que só sabiam ler e escrever. Agora, imagine dar a eles um par de olhos. Isso é, em essência, um Modelo de Visão e Linguagem (VLM - Vision-Language Model). É uma IA que consegue processar e entender informações de múltiplas "modalidades", principalmente texto e imagens, de forma conectada.
Como isso funciona? Pense que o modelo tem duas partes principais em seu "cérebro":
O Especialista em Visão: Uma parte que é treinada para olhar para os pixels de uma imagem e convertê-los em conceitos. Ele não vê apenas "manchas coloridas", ele identifica objetos, texturas, ações e a relação entre eles (ex: "um gato fofo dormindo sobre um sofá vermelho").
O Especialista em Linguagem: É o LLM que já conhecemos, mestre em gramática, contexto e conhecimento de mundo.
A mágica acontece porque essas duas partes são treinadas juntas com bilhões de exemplos de imagens e suas respectivas descrições. O especialista em linguagem aprende a associar as palavras "gato fofo dormindo" com os conceitos visuais que o especialista em visão extraiu. Eles aprendem a falar uma "língua" em comum, permitindo tarefas incríveis como descrever uma foto, responder perguntas sobre um vídeo ou até gerar uma imagem a partir de um texto.
Analogia: Imagine um tradutor poliglota que é fluente em Português e em uma língua alienígena chamada "Visualês", a língua das imagens. Quando você mostra uma foto para o VLM, sua parte visual entende a cena em "Visualês" instantaneamente. Em seguida, sua parte de linguagem traduz perfeitamente essa compreensão para o Português para você. O processo inverso também funciona: você fala em Português o que quer, e ele traduz para "Visualês" para criar uma nova imagem.
Imagem ilustrativa gerada pelo Gemini.
2. Interleaving de Múltiplas Modalidades
Fazer o upload de uma imagem e uma pergunta já é impressionante. Mas a verdadeira fronteira da multimodalidade é o "Interleaving", que significa entrelaçar ou misturar texto e imagens em uma única conversa, de forma fluida.
Isso permite que o modelo mantenha o contexto de várias imagens e textos ao mesmo tempo. Você pode mostrar uma imagem, fazer uma pergunta, mostrar outra imagem, fazer uma comparação, e ele se lembrará de tudo o que foi mostrado e dito para formular a resposta.
Vamos ver um exemplo prático. Imagine que você está analisando um relatório financeiro:
Seu prompt poderia ser:
"Analise os seguintes dados. Primeiro, aqui está o gráfico de vendas do ano passado:"
Gráfico de Barras: "Vendas Anuais 2024"
"Agora, veja o gráfico de despesas no mesmo período:"
Gráfico de Pizza: "Despesas Anuais 2024"
"Com base nos dois gráficos, em qual trimestre tivemos o maior lucro líquido (vendas - despesas)? Justifique sua resposta observando os picos de cada gráfico."
Para responder, o modelo precisa:
Extrair os dados visuais do primeiro gráfico.
Extrair os dados visuais do segundo gráfico.
Entender sua pergunta em texto, que conecta os dois gráficos.
Realizar uma operação lógica (comparação e subtração) usando informações de ambas as fontes.
Essa capacidade de raciocinar sobre múltiplas fontes de informação, visuais e textuais, é o que torna o interleaving uma técnica tão poderosa.
Analogia: É como mostrar um álbum de fotos para um amigo e contar uma história. Você aponta para uma foto e diz "Aqui estávamos na praia" (imagem + texto). Vira a página, aponta para outra e diz "E aqui, duas semanas depois, na montanha" (outra imagem + outro texto). Então, você pergunta: "Olhando para as duas fotos e lembrando do que eu disse, em qual viagem eu parecia mais bronzeado?". Seu amigo precisa acessar a memória visual das duas fotos e o contexto de tempo que você deu para responder. O Interleaving dá essa mesma capacidade de raciocínio contextual para a IA.

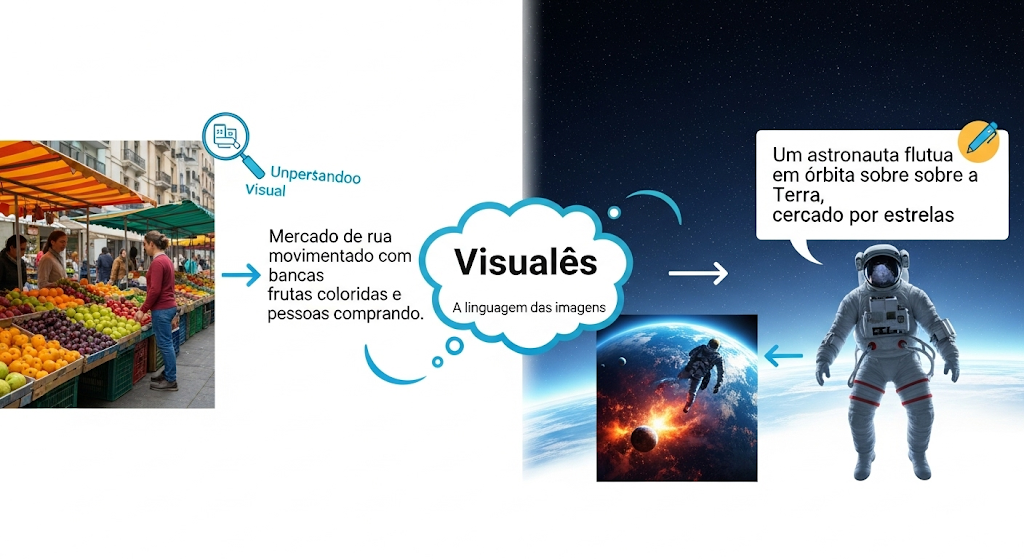
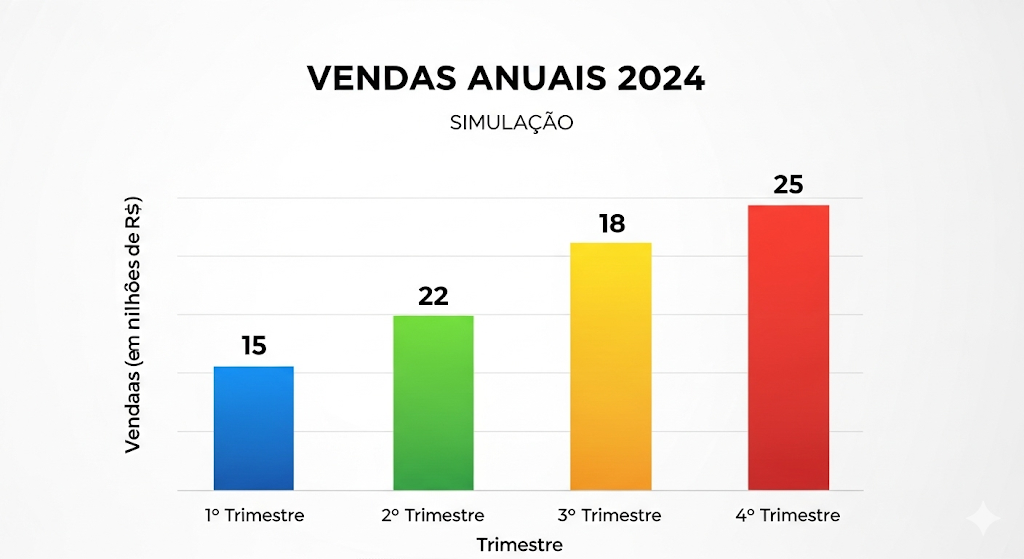 Gráfico de Barras: "Vendas Anuais 2024"
Gráfico de Barras: "Vendas Anuais 2024"
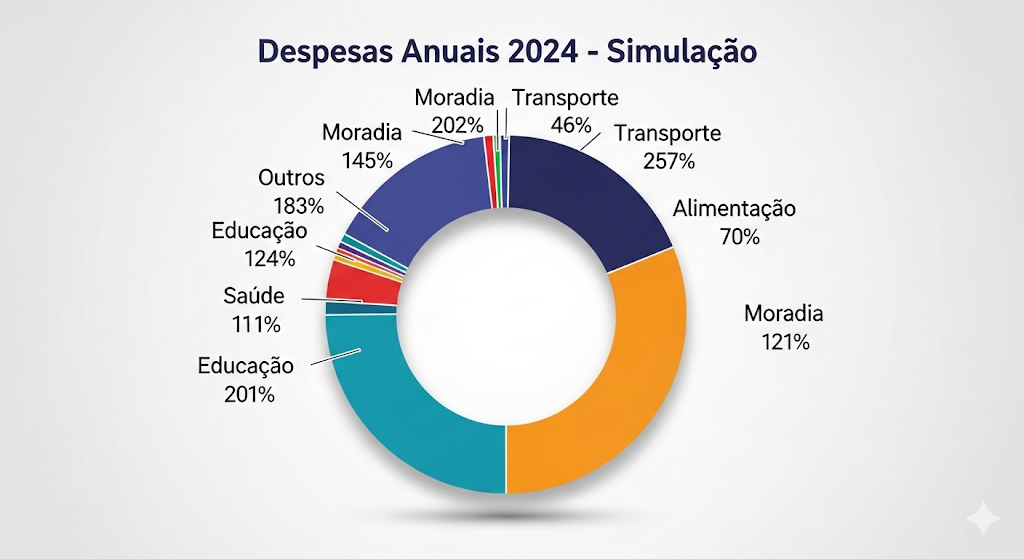 Gráfico de Pizza: "Despesas Anuais 2024"
Gráfico de Pizza: "Despesas Anuais 2024"
